近期《Nature》杂志发表了来自于DeepMind等单位“Highly accurate protein structure prediction with AlphaFold”重磅论文,公开了进一步优化的AlphaFold源代码并详细描述了其设计框架和训练方法。该文章的技术细节显示,电信学院刘文予教授、王兴刚副教授团队提出的十字交叉注意力(CCNet)方法成为了最新版本AlphaFold的重要模块之一,文中称CCNet和Axial-deeplab启发了采用注意力方法来解译蛋白质序列的探索(“CCNet and Axial-deeplab have inspired the exploration of attention-based methods for interpreting protein sequences”)。
AlphaFold能够预测98.5%的人类蛋白质结构,并将预测的准确性提升到了原子级别。而在这之前科学家们数十年的努力,只覆盖了人类蛋白质序列中17%的氨基酸残基。由于AlphaFold在生命科学中巨大的应用潜力,施一公院士评价AlphaFold“这是人工智能对科学领域最大的一次贡献,也是人类在21世纪取得的最重要的科学突破之一,是人类在认识自然界的科学探索征程中一个非常了不起的历史性成就。”由于CCNet中“行自注意力+列自注意力”的新机制对于Transformer中核心的自注意力模块的时空复杂度的显著减低,因此,它能够解决AlphaFold中大尺度蛋白质序列的多序列比对(MSA)表示学习中显存爆炸和计算速度慢的难题。
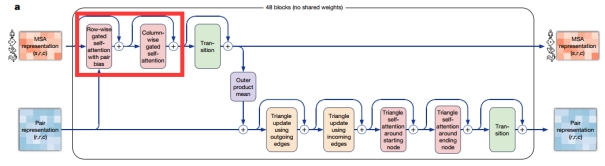
图1:AlphaFold中的多序列比对(MSA)学习模块,其中CCNet提出的
“行自注意力+列自注意力”模块被堆叠了48次
CCNet方法的第一作者为电信学院博士生黄子龙(导师刘文予,副导师王兴刚),通讯作者王兴刚副教授。于2018年发布于arXiv预印版网站,2019年被计算机视觉领域顶级会议ICCV录用(CCNet: Criss-Cross Attention for Semantic Segmentation. IEEE International Conference on Computer Vision (ICCV), 2019:603-612),其拓展版本2020年发表于人工智能顶级期刊IEEE TPAMI(IF 16.389)。论文提出了十字交叉注意力(Criss-Cross Attention)用以高效自适应的全图上下文建模,将Transformer中核心的自注意力结构分解为行自注意力(Row-wise Self Attention)和列自注意力(Column-wise Self Attention),采用连续的两次稀疏自注意力计算来逼近一次稠密的自注意力计算,将Self Attention / Non-local Network的时间复杂度和空间复杂度从O(N2)降低到O(N)。在无人驾驶场景分割问题上,相比于经典的Non-local网络快6.5倍,内存消耗降低了91.4%,且分割准确率更高。
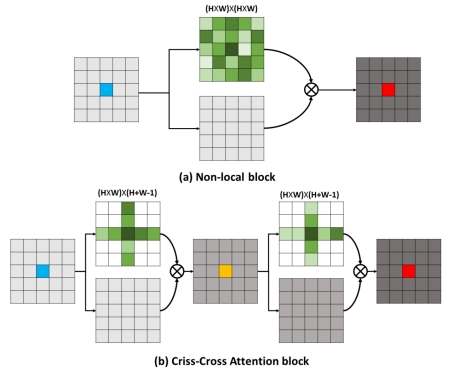
图2:CCNet通过2次十字交叉的稀疏注意力(b)来逼近一次计算稠密
自注意力的Non-local方法
CCNet源代码在GitHub上得到了超过1100 stars,并被纳入到DeepLab系列(谷歌推出的业内最先进的物体分割框架)的最新版本Axial DeepLab中,被UC Berkeley和谷歌大脑的研究人员拓展到处理高维数据的Axial Transformer中,并被主流物体分割框架MMSegmentation集成。CCNet发表一年多的时间,单篇论文Google引用超600次,SCI他引超160次。

